
Published on January 12, 2024
Table of Contents
Overview
In our previous blog post, we discussed treating clusters as cattle and not pets, an extension of the same principle we apply to our workloads. This idea of cluster fleets can be made possible by several tools, one of the more interesting being Cluster API.
Cluster API (CAPI) is a Kubernetes sub-project created by the Cluster Lifecycle SIG, which focuses on providing Kubernetes-style declarative APIs and tooling that automates the entire lifecycle of a Kubernetes cluster. CAPI delivers a set of CRDs, operated by custom controllers, capable of managing the cluster infrastructure in a similar fashion that a Kubernetes application developer would create, deploy, and manage their containerized workloads. This means you can provision entire clusters, including the Nodes, load balancers, and VPCs, through the kubectl apply workflow we all know and love.
Cluster API? Why would I need it?
Great question! Have you (or a loved one) ever been afflicted with any of the following symptoms?
- Overwhelmed with a Kubernetes cluster’s lifecycle management (creation, upgrading, modification, maintenance, and deletion)?
- Are you struggling to build a customized managed Kubernetes platform from scratch that deploys clusters on-demand with specific workloads on different cloud providers?
- Only able to scale to ~20 clusters until the DevOps team managing them slows to a crawl?
If so, Cluster API may be an excellent fit for your needs! Let’s go over how it works and its main components.
Understanding Cluster API
Before going in-depth with the general architecture of CAPI, we need to define a few key concepts:
- Management cluster: This is a Kubernetes cluster on which CAPI and infrastructure providers will run. This management cluster is a prerequisite before being able to use CAPI. In a later post, we’ll talk about how to create the initial management cluster.
-
Managed (workload) cluster: A cluster created by CAPI or manually brought into CAPI management. A
Clusterobject represents this in the management cluster. - Machine: An abstraction for compute infrastructure (VM, bare metal, etc.) that will function as a Kubernetes Node. A managed cluster needs Machines to allow CAPI to create nodes that can host the managed cluster’s control plane and workloads.
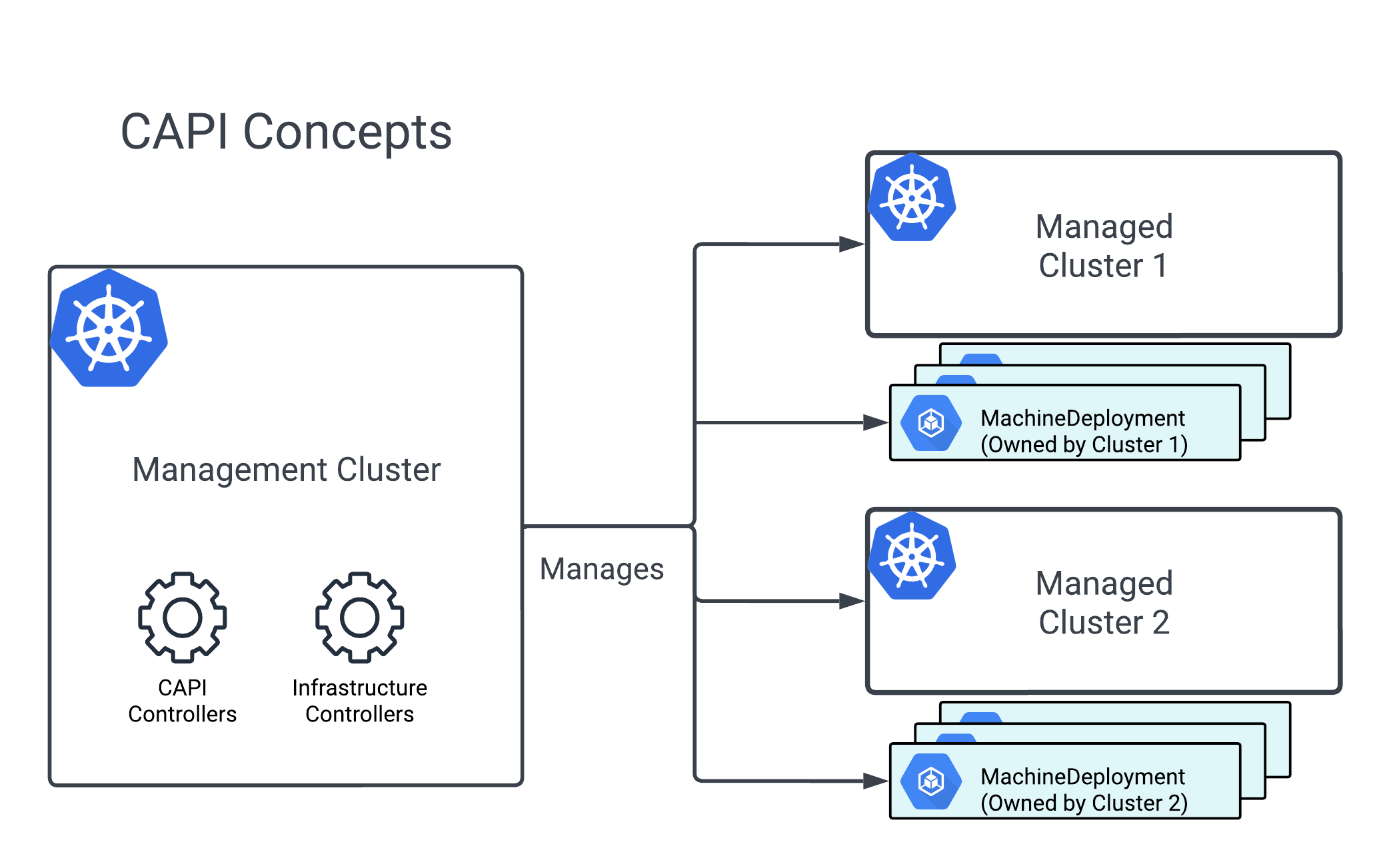
The above diagram showcases how these concepts fall in place architecturally in our infrastructure definition, except… where are the machines? What is this MachineDeployment that’s shown in the diagram? Well, we never really create machines manually – instead, we have CRDs that create and manage them for us!
Controllers and the API
As most Kubernetes-native deployments do, CAPI uses a series of controllers that perform the complex tasks of creating and managing a cluster. These are called custom resource definitions (CRDs) that the user can use to submit custom resources (CRs) to the controllers on the management cluster.
There are three main controllers for CAPI, which all live in capi- prefixed namespaces:
- CAPI core controller
- Control plane controller
- Bootstrap controller
Additionally, there are more controllers for each infrastructure provider that you install on your cluster (GCP, AWS, Azure, etc). Generally speaking, a new controller is added per infrastructure provider, so this needs to be kept in mind when allocating resources for the management cluster.
CAPI core controller
The core primitive API objects in CAPI are the Cluster and Machine objects. The presence of these objects allows the main controller to start the process of bootstrapping the cluster. The Cluster object contains the details of the cluster’s name, how the control plane will be initialized, and the infrastructure provider that the machines will use to create the cluster’s nodes.
Similar to how we never try to create a bare Pod on a node, we also never create a bare Machine for our clusters! The core controller also provides API objects that can manage the lifecycle of a machine. Borrowing from the concepts of Kubernetes, where a Deployment manages a ReplicaSet, which in turn manages individual Pods, CAPI introduces the analogous MachineDeployment and MachineSet.
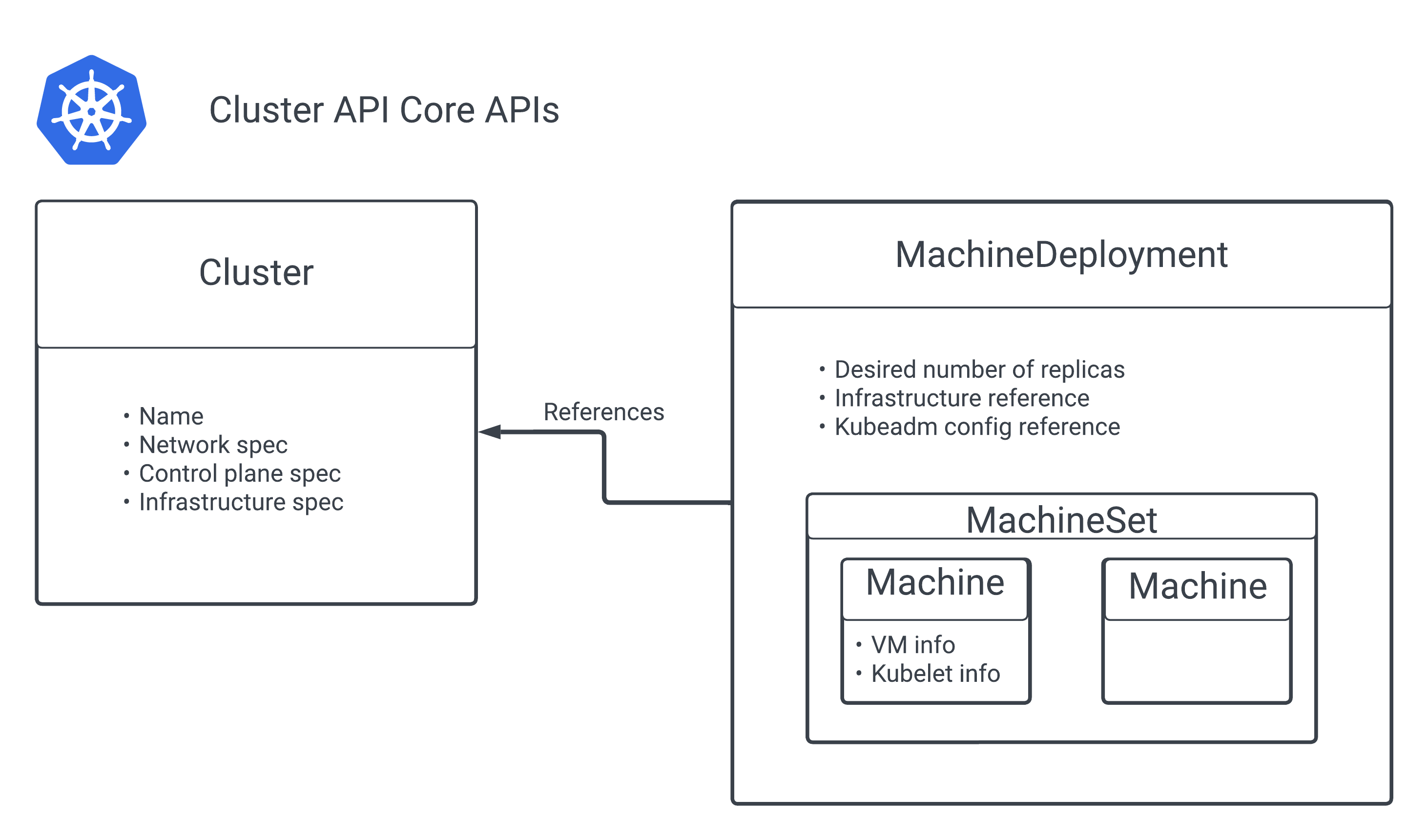
With these, you can describe the desired state in a MachineDeployment, and the CAPI controller will create and delete Machines to reach that state. We can:
- Create a
MachineDeployment, which manages aMachineSetthat createsMachines, and then check the rollout status to see its progress. - Declare the new state of the
Machinesby updating theMachineTemplateSpecof theMachineDeployment. - Scale up
MachineDeploymentsto create moreMachines, or scale down to destroy them.
Due to how infrastructure providers differ, the specifications of the created compute instance are placed in the Machine’s specification as a kind/name reference. This allows for the Machine’s API spec to remain stable while still being able to create instances in different cloud providers.
Infrastructure Providers
No cluster could ever exist without the underlying infrastructure – the VMs, the Load Balancers, the VPCs, and others. Each cloud has their own particular API to fit the nomenclature and structure of the cloud resources being created. For this reason, each cloud or infrastructure provider maintains its own controller that can talk to the cloud-specific API bits and create the resources that CAPI requires for each cluster. These are referred to, fittingly, as “infrastructure providers.” The list of infrastructure providers is pretty extensive, and there’s a likelihood that your favorite cloud provider is on this list. The Big Three (AWS, Azure, and Google) are obviously supported, but bare-metal offerings such as VMWare, Equinix, and Metal3 are there as well.
Each cloud speaks a different language, so the CRD API spec for each infrastructure provider is different. AWS’s API references AMIs for instances created by its infrastructure provider. Due to this, it’s best to look in each provider’s documentation for details on creating and modifying the resources in the cloud. One noteworthy detail is that some providers allow for transferring resources created manually or by other methods, such as Terraform, so don’t be afraid to BYOI (bring your own infrastructure)!
Control Plane controller
The control plane controller is responsible for creating the control plane for the managed cluster. CAPI’s implementation leverages kubeadm’s work and uses it to spin up the required control plane components. For this reason, a KubeadmControlPlane API object can be considered “using kubeadm to create a control plane,” except instead of imperatively running commands on the shell inside your compute instance, a controller is doing the hard work for you.
The most impactful bits of the specification are:
- The
kubeadmConfigSpeccontrols how kubeadm will behave during the steps or phases involved when creating a control plane. Also, it allows for configuring specific control plane components, such as enabling feature gates or adding extra arguments. - The
machineTemplatewill refer to the machine on which the control plane will be installed. Note that it refers to the machine template that needs to exist already. - The
replicasfield specifies how many control plane machines should exist. SinceKubeadmControlPlaneimplements the scale subresource, thekubectl scalecommand can modify the control plane replica count. - The
versionfield denotes the Kubernetes control plane version the controller should deploy.
With this spec, CAPI’s control plane controller will create a control plane with etcd, kube-apiserver, kube-controller-manager, and kube-scheduler. By default, it will additionally install CoreDNS and kube-proxy within the cluster, which aren’t required for a working control plane, but are necessary for a functional cluster. You can optionally skip the installation of these components by setting the skip phases on the initConfiguration field.
The control plane controller also performs a control plane upgrade whenever the Kubernetes version field is incremented. It’ll carefully roll out new versions of the control plane by bringing down a single replica at a time and performing health checks on the new control plane instance before moving on to the next replica.
Bootstrap controller
Compute instances, whether VMs in Google Cloud or a series of Raspberry Pis under your desk, cannot do much Kubernetesing without being a part of the cluster. This is where the bootstrap controller does the heavy lifting – it’s responsible for turning compute instances into Kubernetes nodes.
Additionally, it generates the cluster certificates (if not generated and provided beforehand), initializes the control plane (while pausing the creation of other nodes until the control plane is ready), and joins the control plane and worker nodes to the cluster. The bootstrap configuration allows for customizing the kubelet arguments on worker nodes and control plane nodes – handy when also modifying the feature gates to enable experimental features in a cluster!
Wrapping up
In this part one of our deep dive on declarative cluster management, we looked at Cluster API, its architecture, and how it functions to create a production-ready cluster in any cloud that supports its own provider. In the next part, we’ll do a case study on using Cluster API with one of its infrastructure providers (Cluster API AWS provider or CAPA). We’ll even share our own tool for bootstrapping a management cluster with CAPA installed and ready to go.
Subscribe (yes, we still ❤️ RSS) or join our mailing list below to stay tuned!